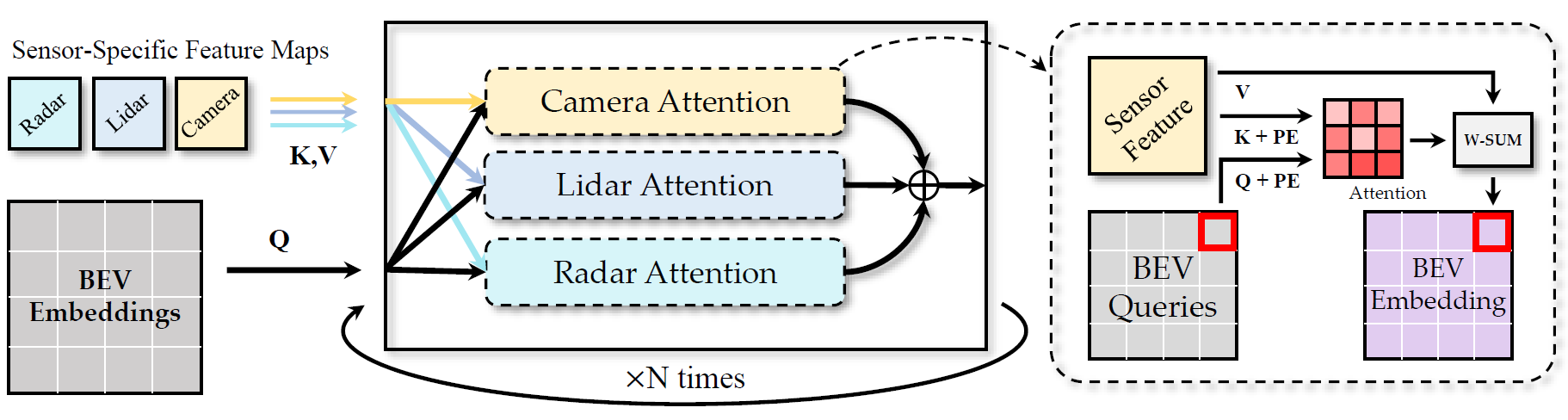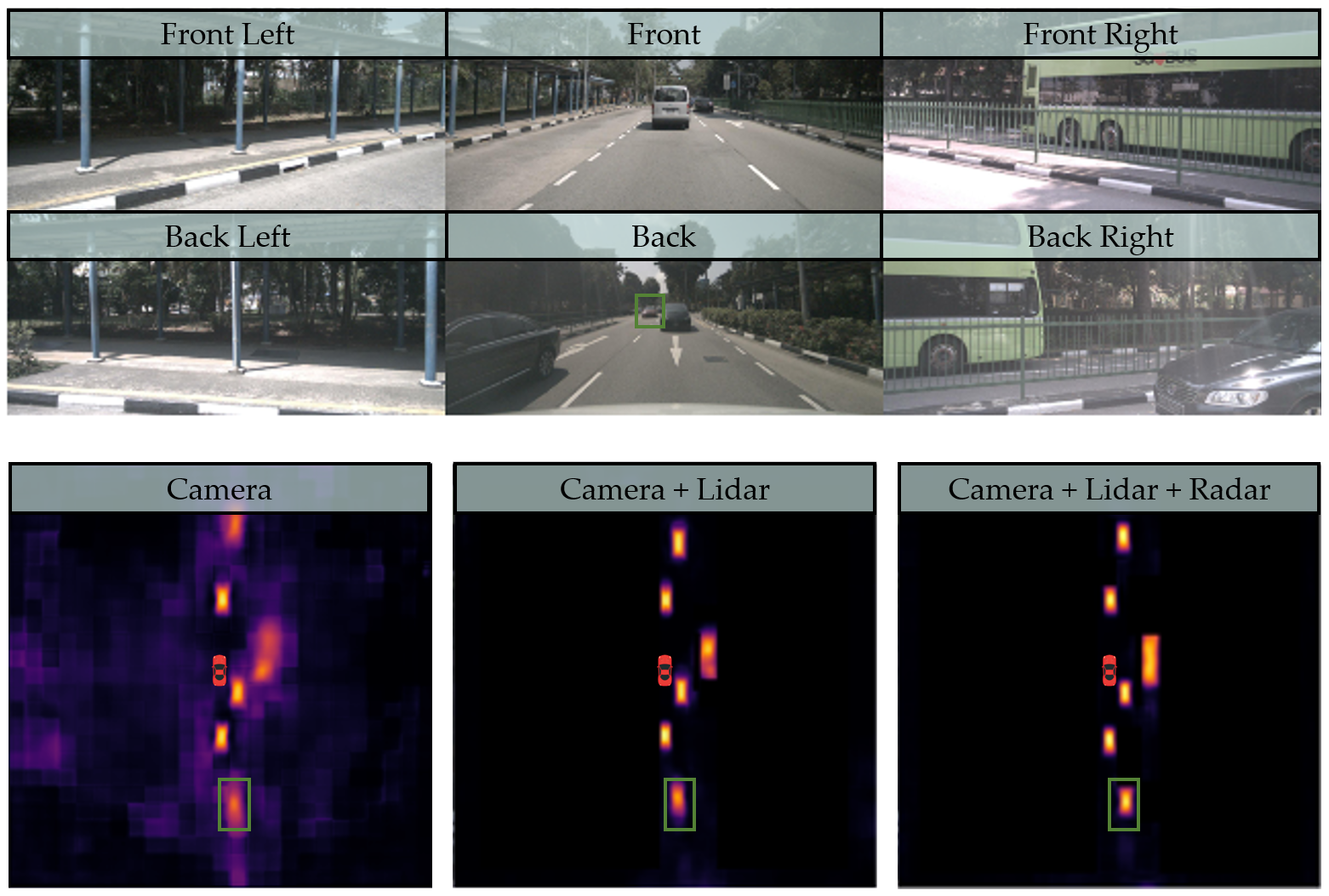
Figure 1. Qualitative results of BEVGuide on vehicle segmentation.
The Lidar helps the model better locate objects in general, and the Radar further improves the perception of distant objects.
The bright (yellow) region means high probability of being vehicle and vice versa.
TL;DR: We propose BEVGuide, a BEV-guided multi-sensor framework for general-purpose driving perception. We support easy integration of diverse sensor sets and flexible driving tasks.
Abstract
Incorporating multiple sensors and addressing diverse tasks in an end-to-end algorithm are challenging yet critical topics for autonomous driving.
Towards this direction, we propose a novel Bird's Eye-View (BEV) representation learning framework \ourwork, which is the very first endeavor to unify a wide spectrum of sensors under direct BEV guidance in an end-to-end manner.
Our architecture takes input from a sensor pool including but not limited to Camera, Lidar and Radar sensors, and extracts BEV feature embeddings using a portable and general transformer backbone.
We design a BEV-guided multi-sensor attention block to take queries from BEV embeddings and learn the BEV representation from sensor-specific features from the encoders.
BEVGuide is efficient due to the light-weight backbone design and is flexible as it supports almost any input sensor configurations.
Extensive experiments demonstrate that our framework achieves leading performance in BEV perception tasks with a diverse sensor set.
Model
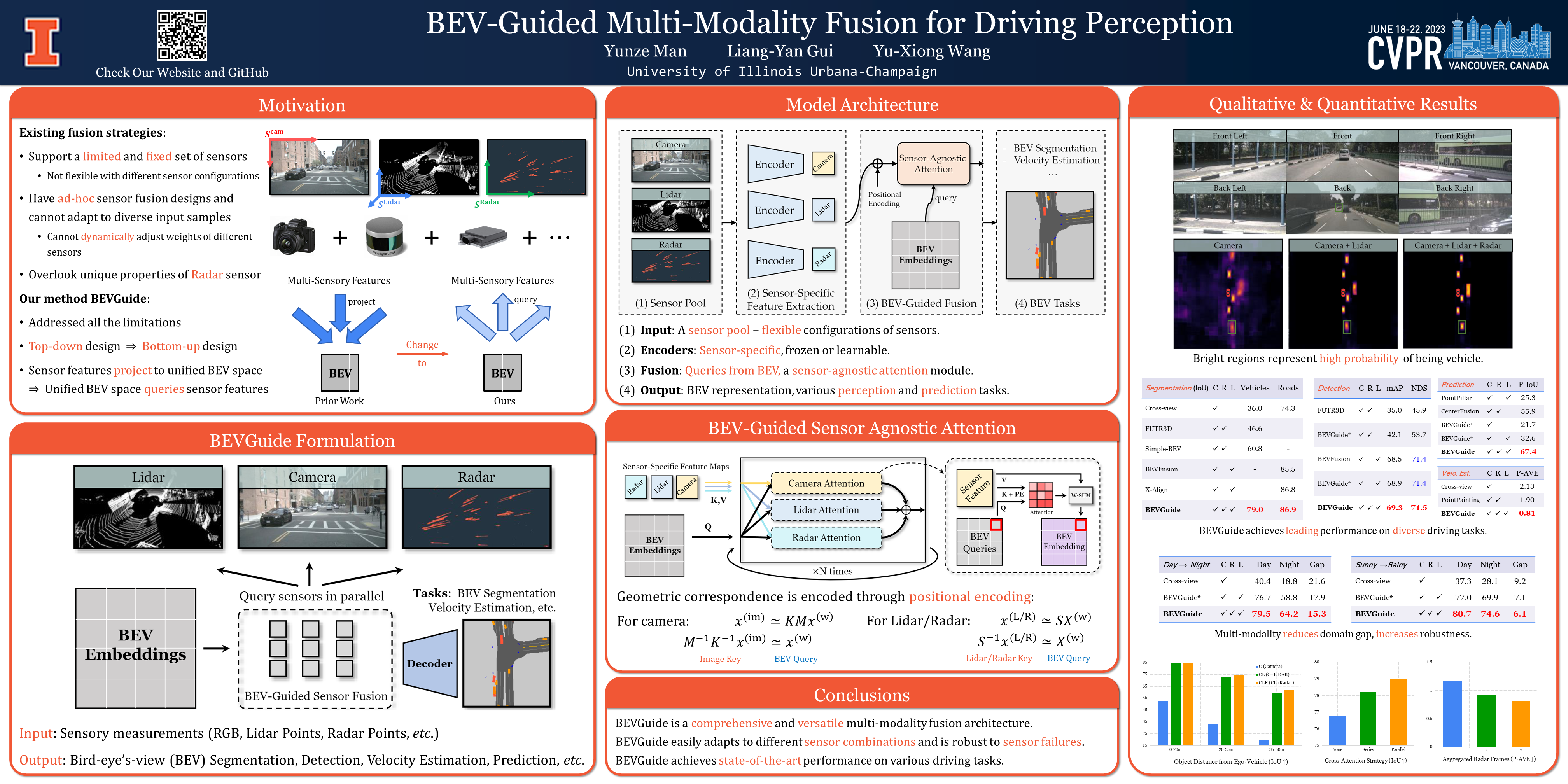
BEVGuide Paradigm. Our proposed method is able to work with any collection of sensors and fuse the feature representation using a BEV-guided transformer backbone. (1) BEVGuide takes input from a sensor pool, and
(2) extracts sensor-specific features.
(3) Then a BEV-guided multi-sensor fusion model takes queries from BEV embeddings and learn BEV features using a sensor-agnostic attention module.
(4) The learned BEV representation will be decoded for the final perception tasks.
For more details please refer to our paper.
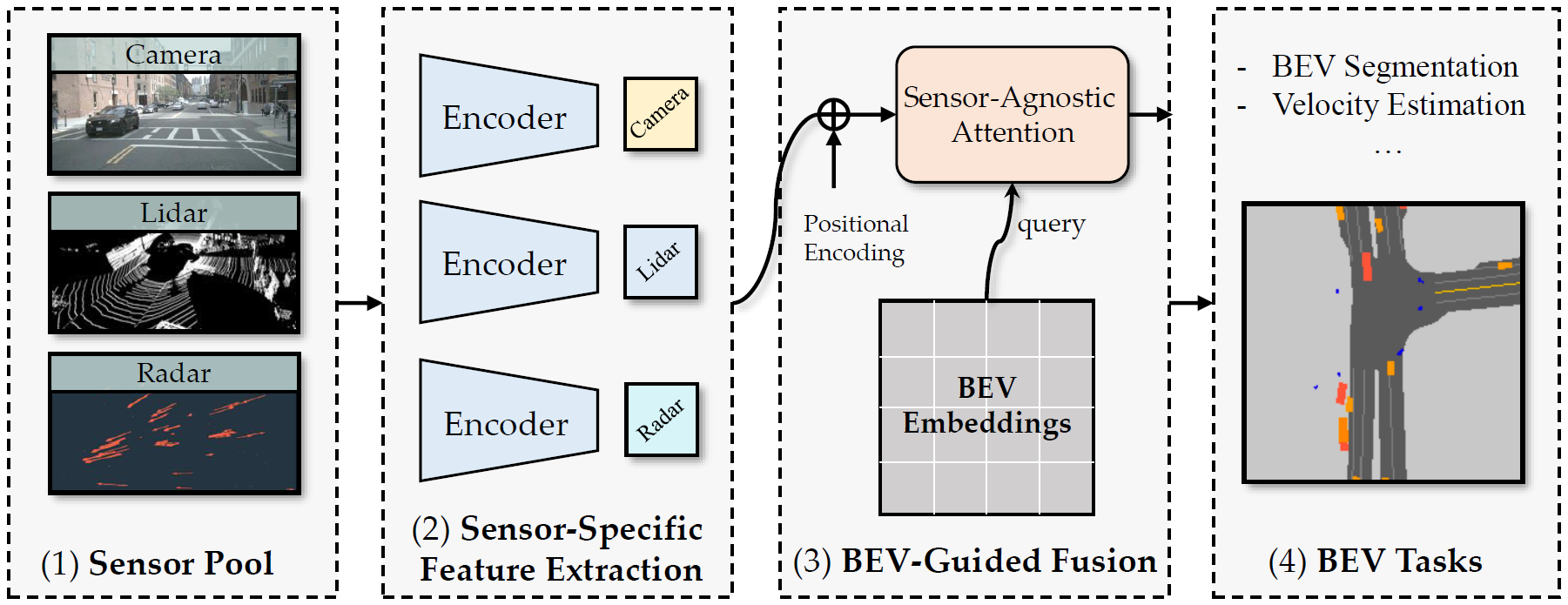
BEV-Guided Sensor-Agnostic Attention
Left: the module takes queries from BEV embeddings, and takes keys and values from sensor-specific feature maps. We use parallel attention modules to extract features from multiple sensors.
Right: the detailed sensor-agnostic attention module. The BEV queries learn an attention map and extract the final BEV representation from the sensory feature maps.
PE and W-SUM stand for positional encoding and weighted summation, respectively.
K, V and Q represent keys, values, and queries, respectively.
For more details please refer to our paper.
Citation
@inproceedings{Man2023_BEVGuide,
author = {Man, Yunze and Gui, Liang-Yan and Wang, Yu-Xiong},
booktitle={CVPR},
title = {{BEV-Guided Multi-Modality Fusion for Driving Perception}},
year = {2023}
}