We design a unified framework, as shown in the Figure above, to extract features from different foundation models, construct a 3D feature embedding as scene embeddings, and evaluate them on multiple downstream tasks. For a complex indoor scene, existing work usually represents it with a combination of 2D and 3D modalities. Given a complex scene represented in posed images, videos, and 3D point clouds, we extract their feature embeddings with a collection of vision foundation models. For image- and video-based models, we project their features into 3D space for the subsequent 3D scene evaluation tasks with a multi-view 3D projection module.
We visualize the scene features extracted by the vision foundation models in Figure below.
The visualizations reveal several intuitive findings. The image models, DINOv2 and LSeg, demonstrate strong semantic understanding, with LSeg exhibiting clearer discrimination due to its pixel-level language semantic guidance. The diffusion-based models, SD and SVD, in addition to their semantic modeling, excel at preserving the local geometry and textures of the scenes, because of the generation-guided pretraining. The video models, SVD and V-JEPA, showcase a unique ability to identify different instances of the same semantic concepts, such as the two trees in the first scene and the chairs in both scenes. The 3D model, Swin3D, also exhibits strong semantic understanding. However, due to limited training data and domain shift, its quality is not on par with the image foundation models, despite being pretrained on perfect semantic annotations.
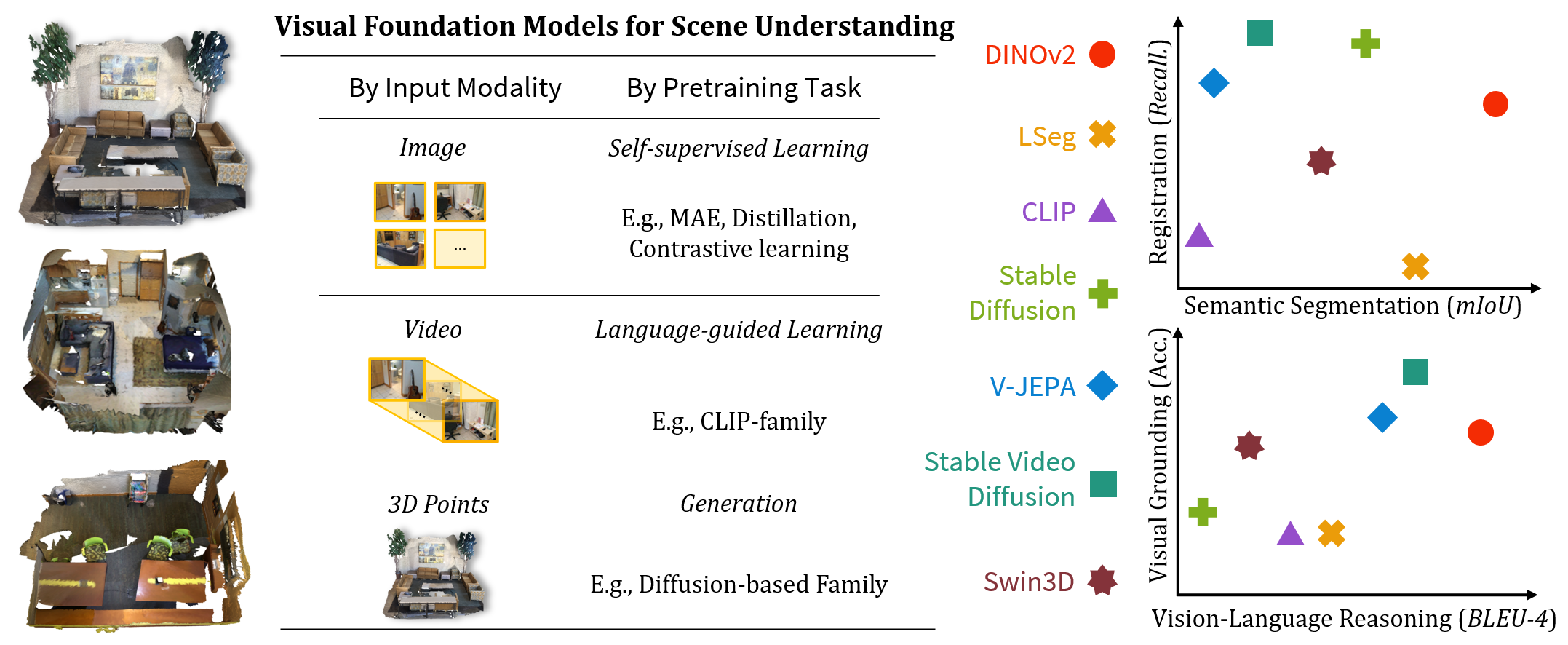 Evaluation settings (left) and major results (right) of different vision foundation models for complex 3D scene understanding. We probe visual foundation models of different input modalities and pretraining objectives, assessing their performance on multi-modal scene reasoning, grounding, segmentation, and registration tasks.
Evaluation settings (left) and major results (right) of different vision foundation models for complex 3D scene understanding. We probe visual foundation models of different input modalities and pretraining objectives, assessing their performance on multi-modal scene reasoning, grounding, segmentation, and registration tasks.
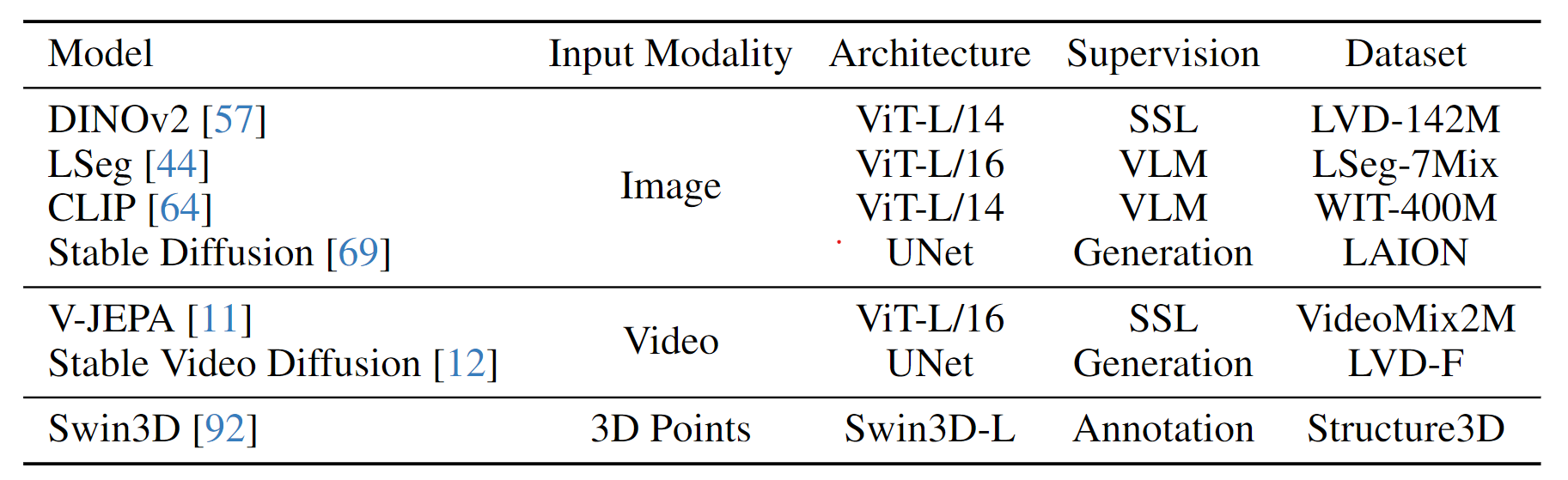 Details of the seven evaluated visual encoding models, including their input modalities, pretraining objectives, architectures, and the training datasets used.
Details of the seven evaluated visual encoding models, including their input modalities, pretraining objectives, architectures, and the training datasets used.
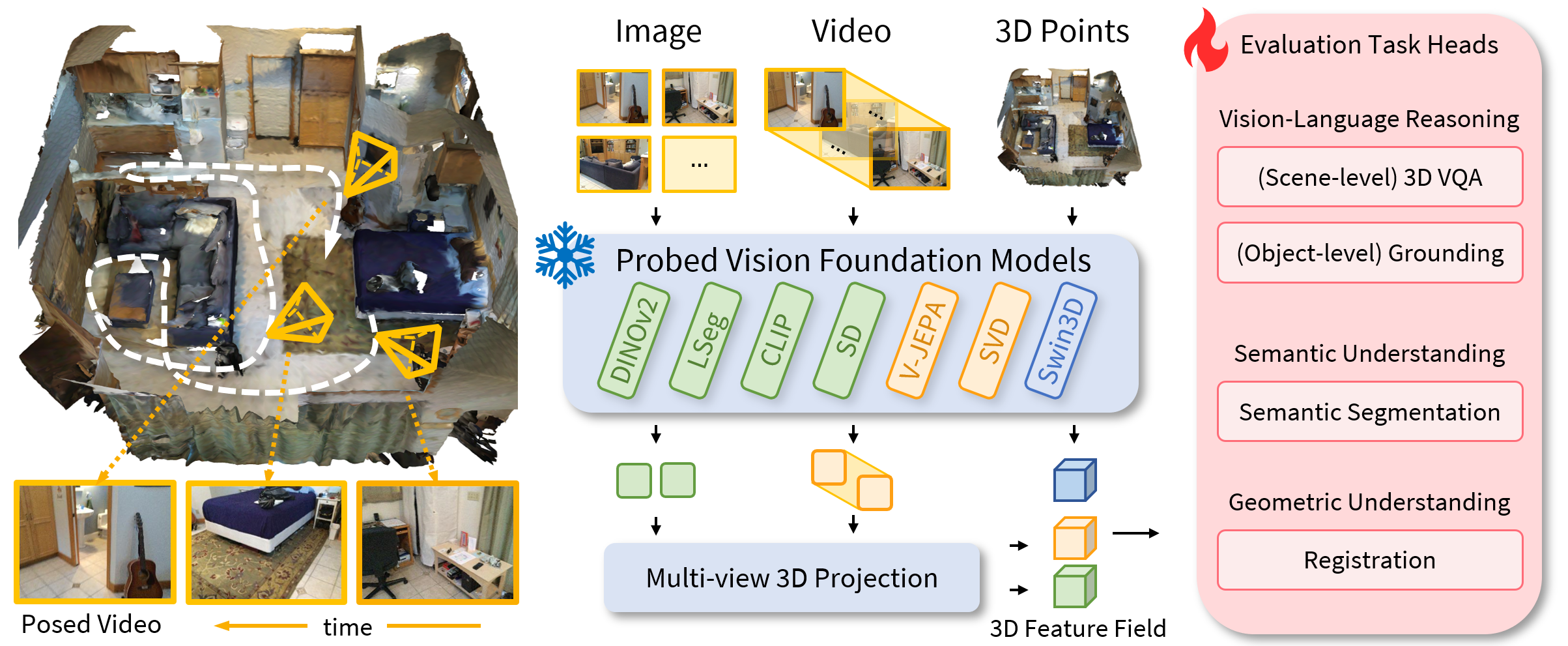 Our unified probing framework to evaluate visual encoding models on various tasks.
Our unified probing framework to evaluate visual encoding models on various tasks.
 Visualizations of extracted scene features from different visual encoders using PCA. The clear distinction between colors and patterns demonstrates the behaviors of different models.
Visualizations of extracted scene features from different visual encoders using PCA. The clear distinction between colors and patterns demonstrates the behaviors of different models.
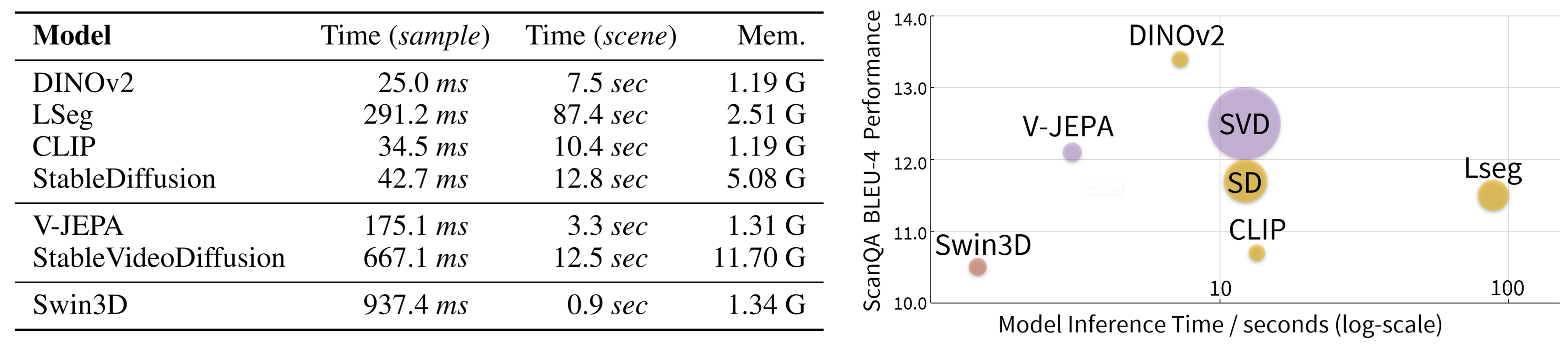 (Left) Complexity analysis of visual foundation models. (Right) Memory usage of different encoders. An ideal model should be a small circle and be positioned in the upper left.
(Left) Complexity analysis of visual foundation models. (Right) Memory usage of different encoders. An ideal model should be a small circle and be positioned in the upper left.